
Langsmith is a library for debugging, testing, evaluating, and monitoring chains and intelligent agents built with the Langchain library (or any other LLM library).
Table of Contents
- Prompt
- Classification service
- Configuring Langsmith
- Monitoring
- Searching for traces
- Adding Feedback in the UI
- Adding Feedback Using API
In this article, I’ll demonstrate the use of Langsmith for tracking interactions with an OpenAI model, along with gathering feedback about the model’s response quality. We will build an article classification application that determines whether a given article describes an environmental impact of an event. Our application will return information on whether the event is relevant to our needs, assign the event to a category, summarize the article, and extract information about the event’s location.
Prompt
We want to get lots of information from the article, yet a single prompt suffices. In the prompt, we tell the model what behavior we expect and describe the output format:
Given the following article, determine:
* if it describes an event that has an environmental impact
* the category of the event (fire, pollution, oil spill, etc.)
* location of the event
Additionally, generate a one-sentence-long summary in English.
Return the result in the form of a JSON with fields: "is_relevant" (true or false), "category", "location", and "summary".
Don't include the article in the response.
------
{article_content}
Classification service
We build a REST service with Flask. The service receives the article’s text and returns a JSON object with the classification results.
import json
from flask import Flask, jsonify, request
from langchain import PromptTemplate, OpenAI, LLMChain
def classify_article_with_llm(article_content, correlation_id):
prompt_template = """Given the following article, determine:
* if it describes an event that has an environmental impact
* the category of the event (fire, pollution, oil spill, etc.)
* location of the event
Additionally, generate a one-sentence-long summary in English.
Return the result in the form of a JSON with fields: "is_relevant" (true or false), "category", "location", and "summary".
Don't include the article in the response.
------
{article_content}
"""
llm = OpenAI(temperature=0)
llm_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(prompt_template)
)
response = llm_chain(article_content, metadata={"correlation_id": correlation_id})
response = response['text'].strip()
return json.loads(response)
app = Flask(__name__)
@app.route("/", methods=["POST"])
def classify_article():
data = request.get_json()
correlation_id = request.headers.get("X-Correlation-Id")
article_content = data["article"]
response = classify_article_with_llm(article_content, correlation_id)
return jsonify(response)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=True)
In addition to the article’s content, we pass the correlation ID as the metadata. We will use the correlation id to identify the request in the monitoring system.
Configuring Langsmith
To use Langsmith, we will need an API key which we can generate in the settings:
Next, we create a new project in the Project tab. Alternatively, we could send all the data to the default project, but I recommend configuring monitoring properly from the beginning so we don’t need to fix any problems later.
When we have the API key and the project name, we can configure Langchain to use Langsmith for tracking. All we need is four environment variables + the OpenAI’s API key:
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
export LANGCHAIN_API_KEY="ls__..."
export LANGCHAIN_PROJECT="article_classifier"
export OPENAI_API_KEY="sk-..."
Monitoring
Now, we can start the service and send a request to it.
Langchain will store every request in the Traces table of Langsmith. We will see not only the first request but also all underlying interactions with LLMs and Langchain agents.
In our example, we have only a single call to an LLM.
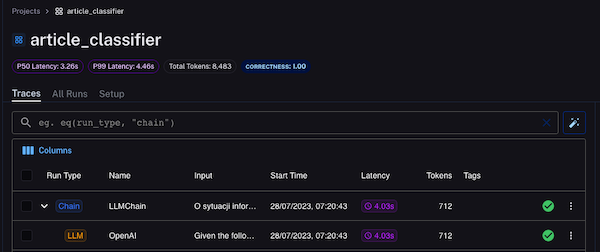
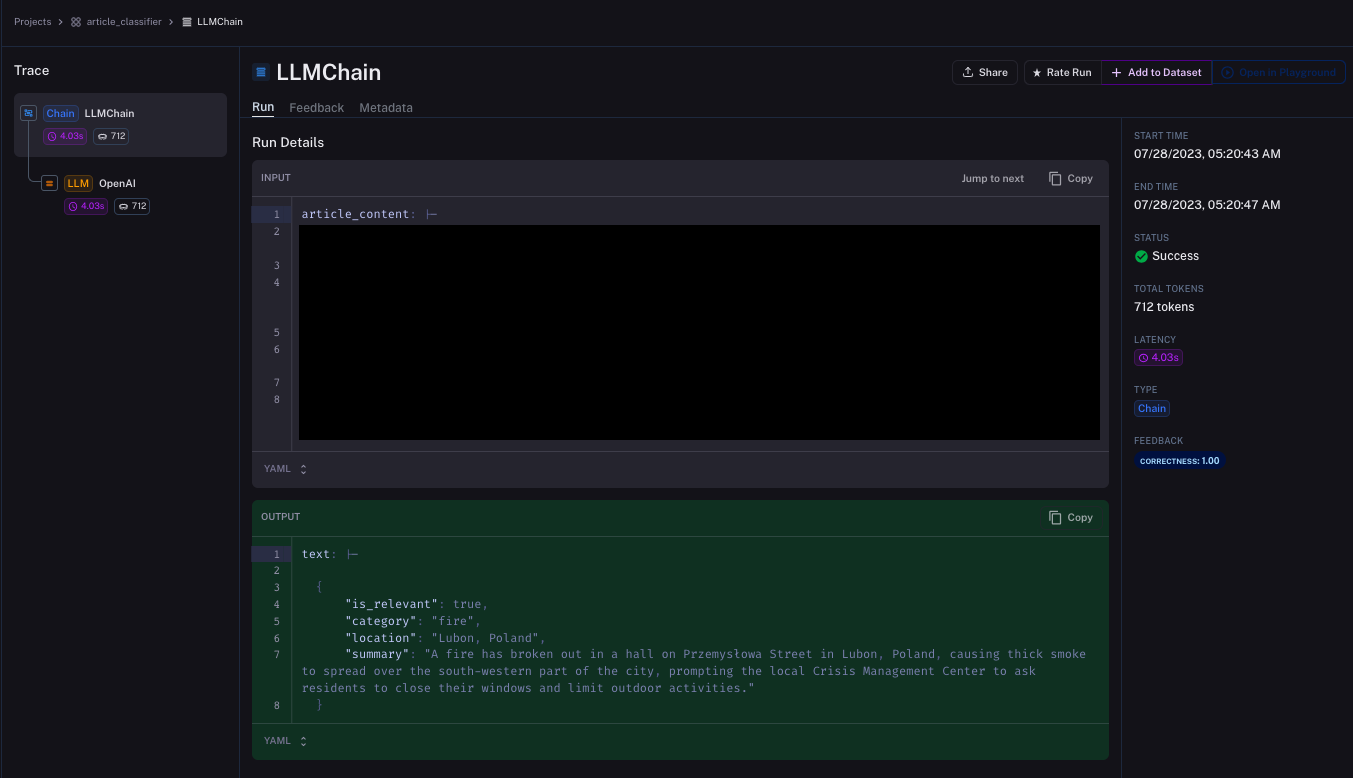
When we click it, we will see the request details, including the request and response bodies, the LLM interaction, and the metadata. I copied the article from a local news website, so I must hide the content to avoid infringing the copyright.
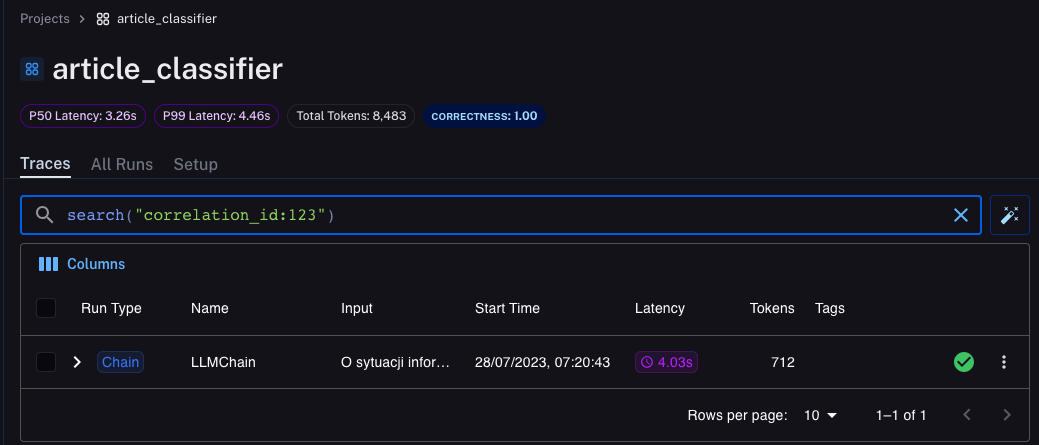
Searching for traces
We can search for traces by the correlation ID. We will need such a search when someone complains about poor model performance, and we have to debug the issue. In the Traces tab, we can use the full-text search to find traces by any property.
Adding Feedback in the UI
The simplest way to store feedback about the model’s performance is by opening the Feedback tab and using the Rate Run function. In the example, I have already rated the run as correct:
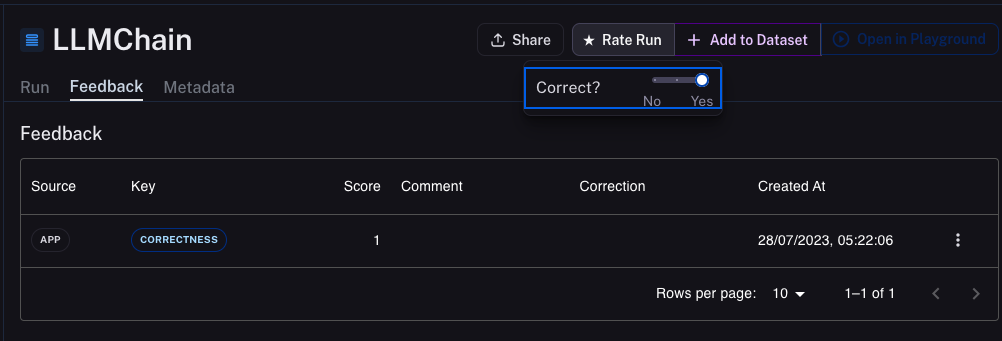
Adding Feedback Using API
Of course, it’s possible to store feedback using the API. Let’s assume we know the correlation id of the request and the classification disappointed the user, so we want to store the zero score as the correctness rating.
First, we have to find the run by the correlation id. When we have the run, we can use its id to create the feedback. Because a single run can have multiple feedbacks, we can store feedback from multiple users.
# Remember about the environment variables defined earlier!
from langsmith import Client
client = Client()
result = client.list_runs(
project_name="article_classifier",
filter='search("correlation_id:123")'
)
for run in result:
_id = run.id
feedback = client.create_feedback(
_id,
"Correctness",
score=0,
comment="This is not an environmental event."
)
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn