
How can we scrape a single website? In this case, we don’t want to follow any links. The topic of following links I will describe in another blog post.
Table of Contents
First of all, we will use Scrapy running in Jupyter Notebook. Unfortunately, there is a problem with running Scrapy multiple times in Jupyter. I have not found a solution yet, so let’s assume for now that we can run a CrawlerProcess only once.
Scrapy Spider
In the first step, we need to define a Scrapy Spider. It consists of two essential parts: start URLs (which is a list of pages to scrape) and the selector (or selectors) to extract the interesting part of a page. In this example, we are going to extract Marilyn Manson’s quotes from Wikiquote.
import scrapy
from scrapy.crawler import CrawlerProcess
class MarilynMansonQuotes(scrapy.Spider):
name = "MarilynMansonQuotes"
start_urls = [
'https://en.wikiquote.org/wiki/Marilyn_Manson',
]
def parse(self, response):
for quote in response.css('div.mw-parser-output > ul > li'):
yield {'quote': quote.extract()}
process = CrawlerProcess()
process.crawl(MarilynMansonQuotes)
process.start()
Let’s look at the source code of the page. The content is inside a div with “mw-parser-output” class. Every quote is in a “li” element. We can extract them using a CSS selector.
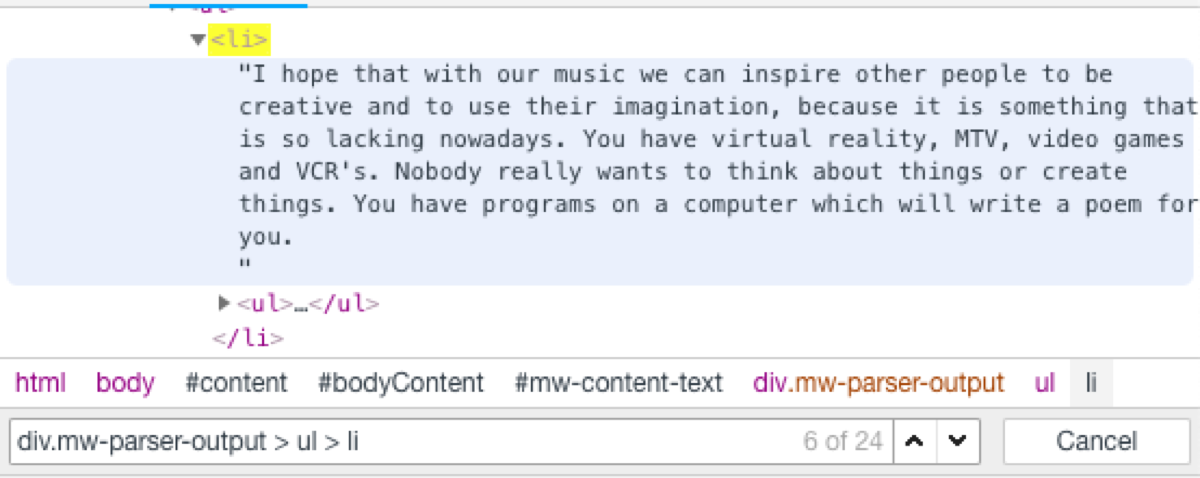
What do we see in the log output? Things like this:
{'quote': "<li>I hope that with our music we can inspire other people to be creative and to use their imagination, because it is something that is so lacking nowadays. You have virtual reality, MTV, video games and VCR's. Nobody really wants to think about things or create things. You have programs on a computer which will write a poem for you.\n<ul><li>As quoted in <i>Kerrang!</i> (14 December 1996).</li></ul></li>"}
It is not a perfect output. I don’t want the source of the quote and HTML tags. Let’s do it in the most trivial way because it is not a blog post about extracting text from HTML. I am going to split the quote into lines, select the first one and remove HTML tags.
Processing pipeline
The proper way of doing processing of the extracted content in Scrapy is using a processing pipeline. As the input of the processor, we get the item produced by the scraper and we must produce output in the same format (for example a dictionary).
import re
class ExtractFirstLine(object):
def process_item(self, item, spider):
lines = dict(item)["quote"].splitlines()
first_line = self.__remove_html_tags__(lines[0])
return {'quote': first_line}
def __remove_html_tags__(self, text):
html_tags = re.compile('<.*?>')
return re.sub(html_tags, '', text)
It is easy to add a pipeline item. It is just a part of the custom_settings.
class MarilynMansonQuotesFirstLineOnly(scrapy.Spider):
name = "MarilynMansonQuotesFirstLineOnly"
start_urls = [
'https://en.wikiquote.org/wiki/Marilyn_Manson',
]
custom_settings = {
'ITEM_PIPELINES': {'__main__.ExtractFirstLine': 1},
}
def parse(self, response):
for quote in response.css('div.mw-parser-output > ul > li'):
yield {'quote': quote.extract()}
def __remove_html_tags__(self, text):
html_tags = re.compile('<.*?>')
return re.sub(html_tags, '', text)
There is one strange part of the configuration. What is the in the dictionary? What does it do? According to the documentation: “The integer values you assign to classes in this setting determine the order in which they run: items go through from lower valued to higher valued classes.”
What does the output look like after adding the processing pipeline item?
{'quote': "I hope that with our music we can inspire other people to be creative and to use their imagination, because it is something that is so lacking nowadays. You have virtual reality, MTV, video games and VCR's. Nobody really wants to think about things or create things. You have programs on a computer which will write a poem for you."}
Much better, isn’t it?
Write to file
I want to store the quotes in a CSV file. We can do it using a custom configuration. We need to define a feed format and the output file name.
import logging
class MarilynMansonQuotesToCsv(scrapy.Spider):
name = "MarilynMansonQuotesToCsv"
start_urls = [
'https://en.wikiquote.org/wiki/Marilyn_Manson',
]
custom_settings = {
'ITEM_PIPELINES': {'__main__.ExtractFirstLine': 1},
'FEED_FORMAT':'csv',
'FEED_URI': 'marilyn_manson.csv'
}
def parse(self, response):
for quote in response.css('div.mw-parser-output > ul > li'):
yield {'quote': quote.extract()}
Logging
There is one annoying thing. Scrapy logs a vast amount of information.
Fortunately, it is possible to define the log level in the settings too. We must add this line to custom_settings:
custom_settings = {
'LOG_LEVEL': logging.WARNING,
'ITEM_PIPELINES': {'__main__.ExtractFirstLine': 1},
'FEED_FORMAT':'csv',
'FEED_URI': 'marilyn_manson.csv'
}
Remember to import logging!