
The task is easy. I have a DataFrame which has missing values, but I don’t know where they are. I want to get a DataFrame which contains only the rows with at least one missing values.
If I look for the solution, I will most likely find this:
data[data.isnull().T.any().T]
It gets the job done, and it returns the correct result, but there is a better solution. Before I describe the better way, let’s look at the steps done by the popular method.
First, it calls the “isnull” function. As a result, I get a DataFrame of booleans. Every value tells me whether the value in this cell is undefined.
data.isnull()

What is T? It is the transpose operations. This operations “flips” the DataFrame over its diagonal. Columns become rows, and rows turn into columns.
data.isnull().T

After that, it calls the “any” function which returns True if at least one value in the row is True.
data.isnull().T.any()
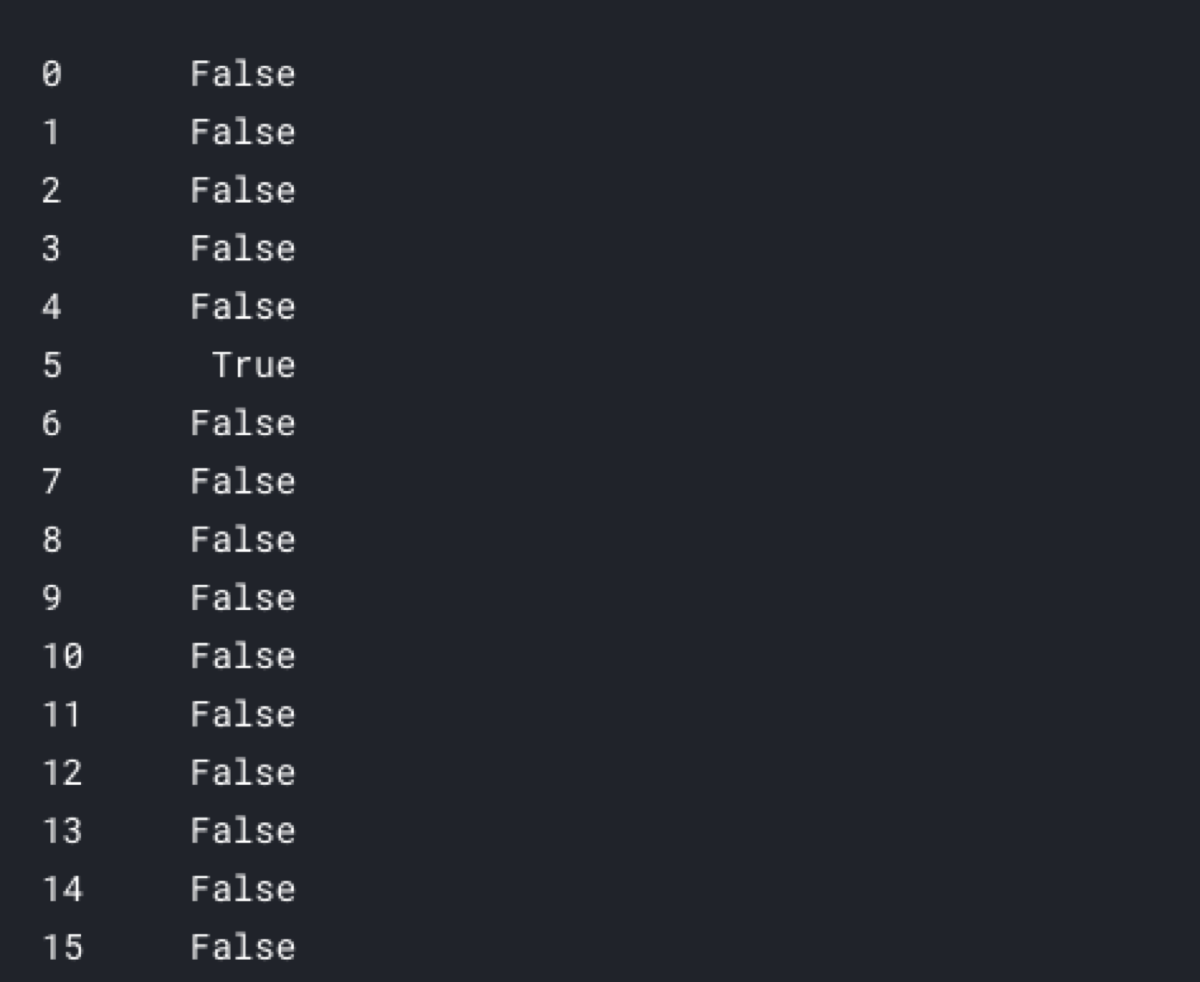
That operation returns an array of boolean values — one boolean per row of the original DataFrame.
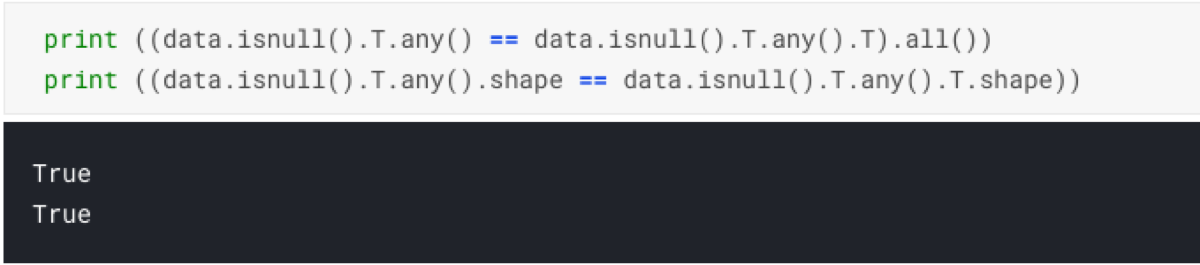
As the last step, it transposes the result. That last operation does not do anything useful. It is redundant. If we look at the values and the shape of the result after calling only “data.isnull().T.any()” and the full predicate “data.isnull().T.any().T”, we see no difference. That is the first problem with that solution.
print ((data.isnull().T.any() == data.isnull().T.any().T).all())
print ((data.isnull().T.any().shape == data.isnull().T.any().T.shape))
Finally, the array of booleans is passed to the DataFrame as a column selector. If a position of the array contains True, the row corresponding row will be returned.
data[data.isnull().T.any().T]
Now, we see that the favored solution performs one redundant operation.In fact, there are two such operations.
If I use the axis parameter of the “any” function, I can tell it to check whether there is a True value in the row.
Because of that I can get rid of the second transposition and make the code simpler, faster and easier to read:
data[data.isnull().any(axis = 1)]