
How much time do you spend tuning Spark parameters? You set the executor memory, the number of cores, the default parallelism parameter. After a few hours of tweaking, you are satisfied with the result and deploy the optimal configuration into production. After a few weeks, the input data changes, and your configuration is no longer optimal. You have to start fiddling around with the Spark configuration again.
You think that maybe using a separate EMR cluster for every Spark job and enabling the “maximize resource allocation” feature will solve all your problems. You no longer have to configure the executor memory and cores, but which instance type should you use? Which one is the cheapest that gets the job done? Fortunately, this time, you have only around sixty possible options. Using a “binary search-like” approach, you will finish in a week or two. And then, the input data changes and your optimal configuration is inadequate again.
Can we do better? Is there a way to tell Spark that I want to run this code, and I don’t want to worry about the configuration?
Jean-Yves (“JY”) Stephan wants to solve that problem. He is the co-founder and CEO of Data Mechanics. His startup, which went through the YCombinator program in 2019, aims to build the simplest way to run Apache Spark, which lets data scientists and engineers focus on the data instead of worrying about the mechanics.
The platform they are building runs your Spark nodes on Kubernetes and automatically tunes the configuration. When you run the same pipeline periodically, for example hourly or daily jobs, their solution starts analyzing Spark logs and automatically finds bottlenecks (e.g. Memory, CPU, I/O) caused by incorrect configuration. During the subsequent pipeline runs, it automatically tweaks the parameters to mitigate those bottlenecks.
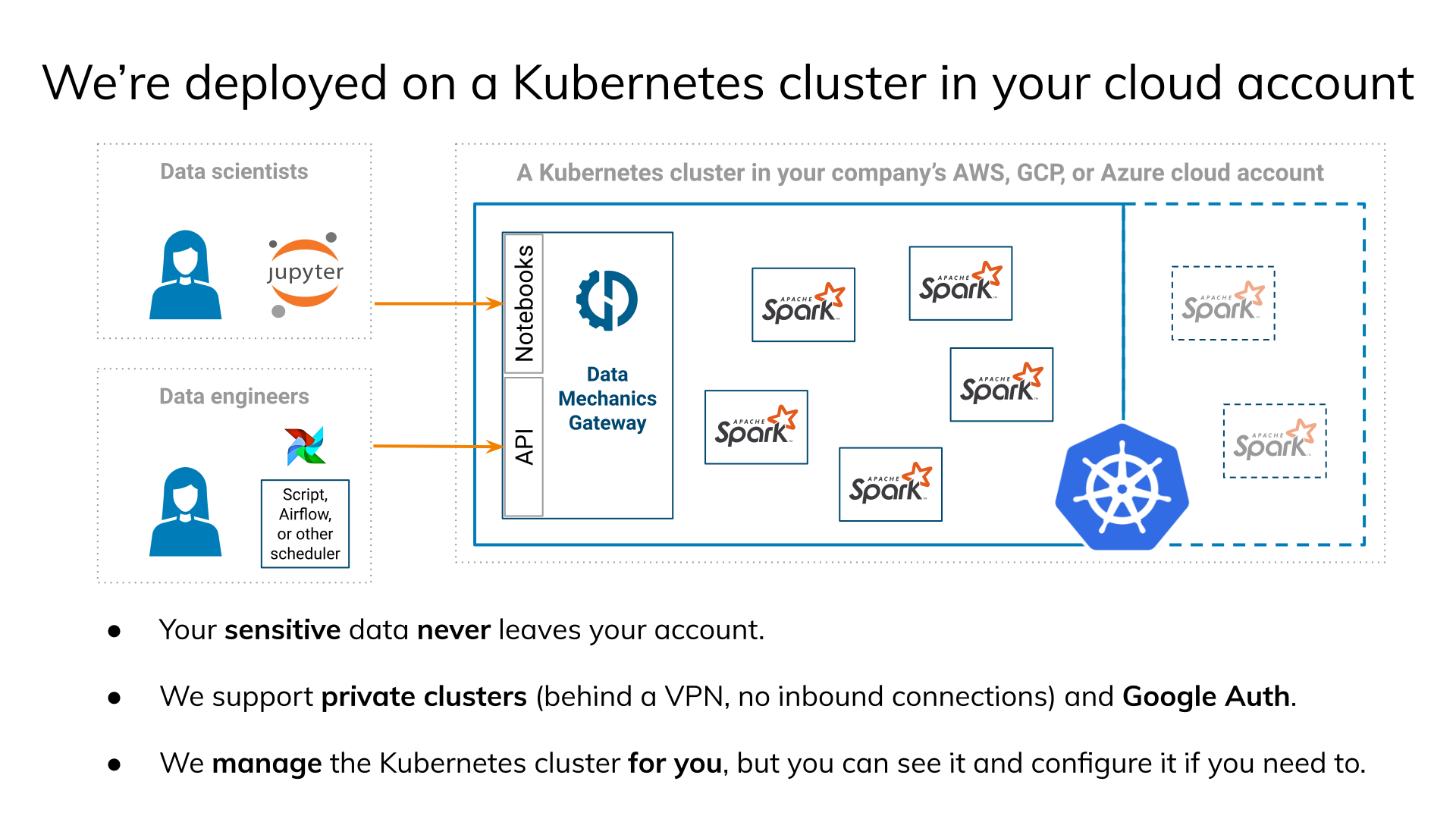
I have to mention that your data stays in your existing cloud infrastructure. You don’t have to copy it to the servers provided by Data Mechanics. It works the other way around. You give them access to your cloud, and they run and manage Spark nodes in your cloud.
That’s why their pricing model is quite interesting. Most Spark platforms (like EMR) charge a fee based on the server uptime: if a node is up, you pay a fee. On Data Mechanics, you only pay for the time when a Spark job managed by their software was running. If a node is up without running any Spark code, you will not pay the Data Mechanics fee. If you use the same machines to run Scala or Python code, you will not pay the Data Mechanics fee either.
Jean-Yves (“JY”) Stephan claims that when their client was using over-provisioned EMR clusters, they were able to reduce the total cost of running Spark down to 30% of the EMR fee that they used to pay. I think that the cost reduction was even more substantial because the data engineers no longer have to spend time tuning Spark, and they can focus on delivering value to the users.

In addition to their serverless Spark service, Data Mechanics are also building Data Mechanics Delight, an improved version of the Spark UI. Besides data already available in the Spark Ui, Data Mechanics Delight will display node metrics such as CPU, memory, and I/O usage.
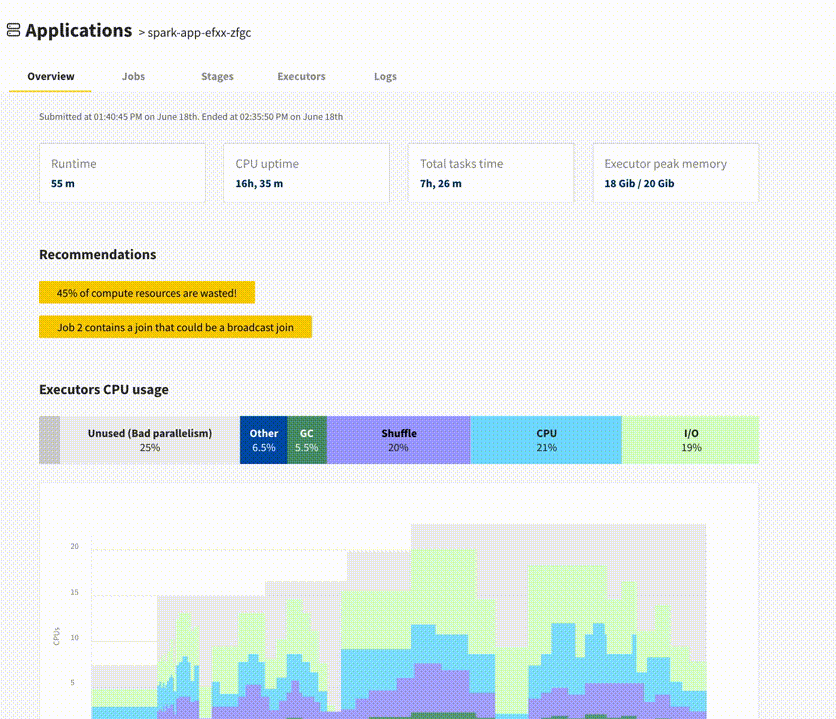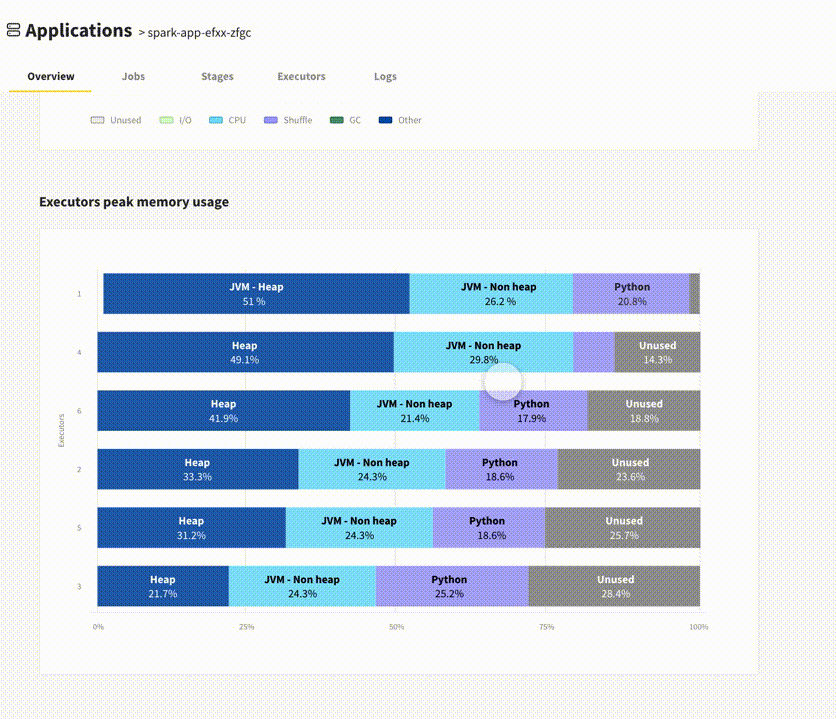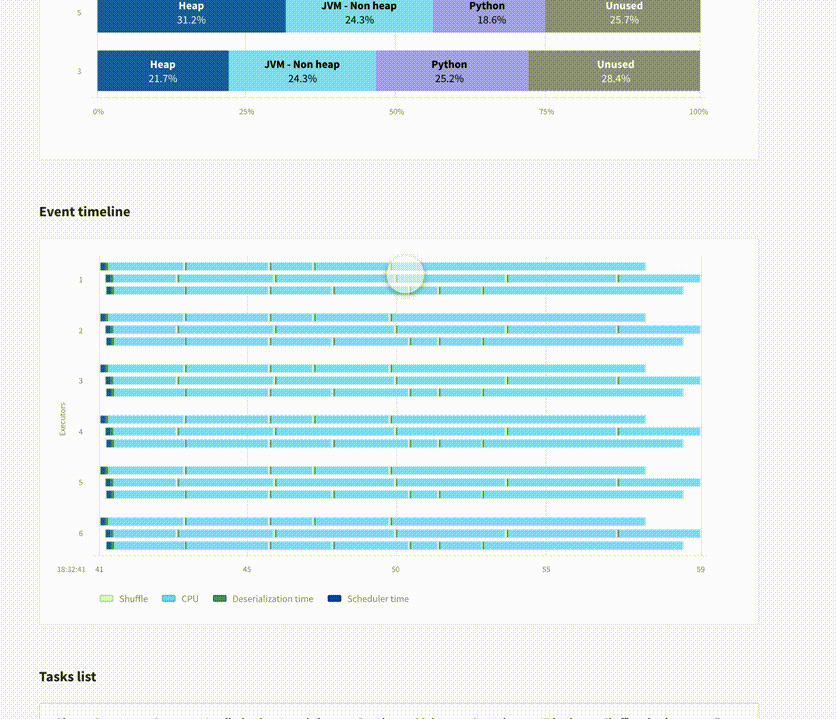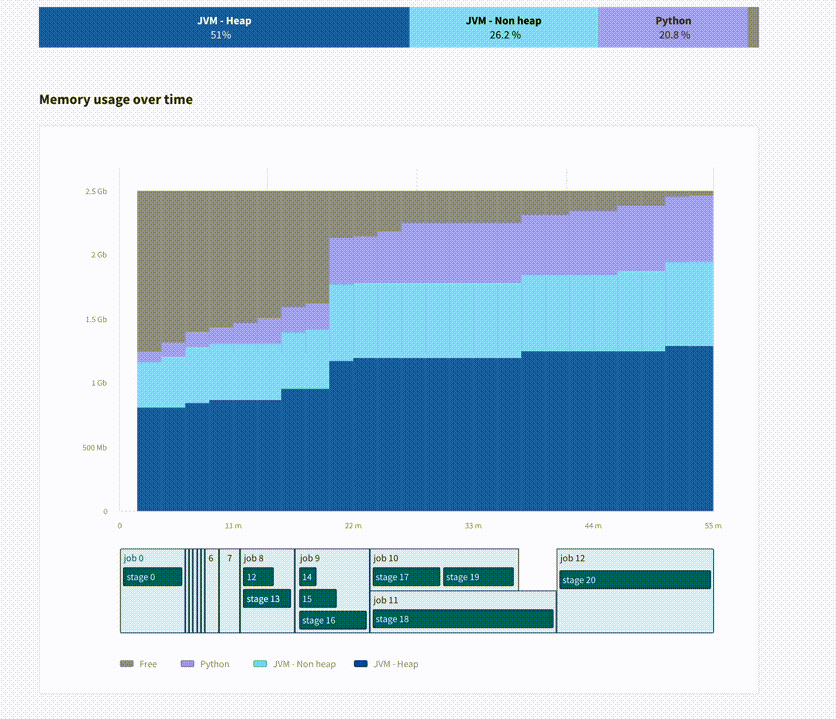
My favorite part is the recommendations, which inform you about problems such as wrong parallelism configuration, skewed input data, or a possibility to use a broadcast join.
What is best, the Data Mechanics team wants to open source the Delight project and make it available to everyone, not only their clients.